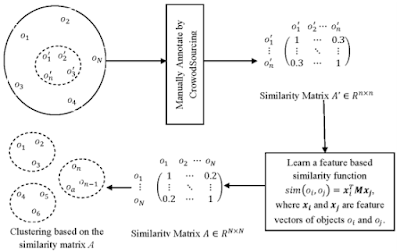
Clustering Algorithms - 9/16-27/19
Below is an extensive video going over what Clustering is in Machine Learning:
This was a video that helped me understand the math behind the EM-Algorithm:
On Thursday we visited Dr. Hassibi and went over what we learned with him. The purpose of doing this was to see if we got any concepts wrong and if so, what can be said/corrected about them. In my opinion, since we have about an hour or less to talk with him, the time should be spent otherwise instead of us presenting what we learned, dwindling the time Dr. Hassibi has to talk. After we all had a turn to demonstrate our understanding, Dr. Hassibi noted that all the topics we learned involved no "graphs." He introduced "Graph Clustering" which involves graphs, which are essentially data structures, instead of data points. An example Dr. Hassibi mentioned was the 1970's Karate Club network problem, an issue that asks if a karate club were to split into two different clubs, what members were likely to side with one club over the other.
This week has been much more engaging with our group's focus on Machine Learning which has really gotten me excited. We are getting into the theory behind such ML subtopics which makes implementing them into projects much easier. In the following few weeks, Mr. Lee and we hope to thoroughly understand Graph Clustering and start writing code for the Karate Club problem. I don't know about others but I'm incredibly eager to be doing this and the program has just begun.


Comments
Post a Comment