Zachary's Karate Club Technical Journal 2
The Problem:
My last technical journal for this dataset can be found on the home page but here's a short
summary: Zachary’s Karate Club is a social network of a karate club that captures 34 members and records links with pairs of interacting members as edges. During the study, the karate club had split into two (between John and Mr. Hi), coincidentally also dividing the members into the two factions. The task at hand is to determine/predict which members would stick with John or leave with Mr. Hi.
The Algorithm:
Previously I've tried many algorithms like K-nearest-neighbor but all of those have proven not
applicable to this graph dataset. However, I was fortunate enough to have found an algorithm that
sounds promising: Community Detection/Girvan-Newman Algorithm. Here's a basic rundown on how the code works:
Girvan-Newman Algorithm (Input: A weighted graph G, Output: A list of components of G):

The Results:
My last technical journal for this dataset can be found on the home page but here's a short
summary: Zachary’s Karate Club is a social network of a karate club that captures 34 members and records links with pairs of interacting members as edges. During the study, the karate club had split into two (between John and Mr. Hi), coincidentally also dividing the members into the two factions. The task at hand is to determine/predict which members would stick with John or leave with Mr. Hi.
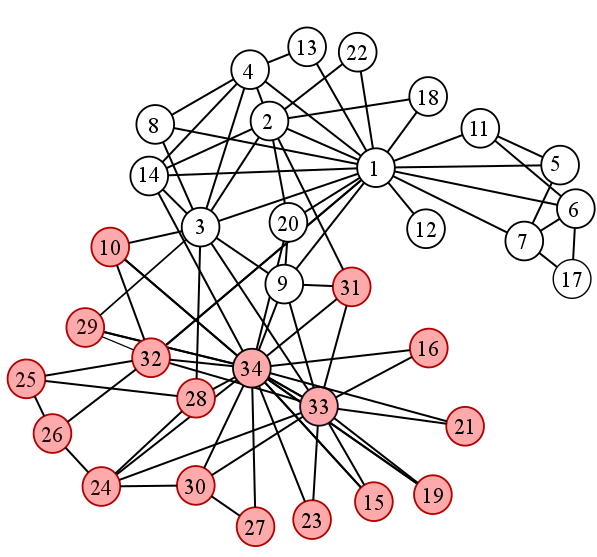
This is an example of an algorithm splitting the 34 members into two groups, indicated by the color difference
The Algorithm:
Previously I've tried many algorithms like K-nearest-neighbor but all of those have proven not
applicable to this graph dataset. However, I was fortunate enough to have found an algorithm that
sounds promising: Community Detection/Girvan-Newman Algorithm. Here's a basic rundown on how the code works:
Girvan-Newman Algorithm (Input: A weighted graph G, Output: A list of components of G):
- BestQ = 0
- Convert the edge matrix into a weighted (0 or 1) social graph G
- Compute the number of components of the graph G (init_ncomp)
- Calculate the weighted version of edge-betweenness for all edges of the graph G
- Find the edge with the highest betweenness and remove it from G
- Compute the number of components in G after edge removal (ncomp)
- If ncomp <= init_ncomp go to back to step 3
- Compute the modularity of the current version of graph G and store it in Q
- If Q > BestQ then saves the current decomposition of G as the best division in BestComps
- If there is not any edge left in G return BestComps otherwise go back to step
For a demonstration on how it works, you can find a video here:
Video showing how Girvan-Newman works on a simple graph
The diagram is a comparison between K-means’ and Spectral’s results.
The Results:
The model had around 94% accuracy with the only nodes being missed are 2 and 8 (indicated
in the red rectangle). I cannot blame the algorithm because so many other models have also
mistaken those two for another cluster. Also, I dropped NMI as a way to display how accurate a model
was because determining that value is fairly simple.

In The Future:
Prior to this edit, I could not get it to work but the error just happened to me forgetting to terminate
a while-loop. In the future, I would like to find more algorithms to test for compatibility. I can conclude
this algorithm a success for now.
in the red rectangle). I cannot blame the algorithm because so many other models have also
mistaken those two for another cluster. Also, I dropped NMI as a way to display how accurate a model
was because determining that value is fairly simple.

Above is what Community Detection predicted
In The Future:
Prior to this edit, I could not get it to work but the error just happened to me forgetting to terminate
a while-loop. In the future, I would like to find more algorithms to test for compatibility. I can conclude
this algorithm a success for now.


Comments
Post a Comment