Technical Journal - Dataset
Ramya Korlakai Vinayak, a graduate from Caltech under Prof. Babak Hassibi, graciously offered us a dataset that was labeled using MTurk (Amazon Mechanical Turk), a crowdsourcing marketplace. The folder contained four MatLab files: Birds5EdgeQuery300workers, Birds5TriangleQuery285workers, Dogs3EdgeQuery300workers, and Dogs3TriangleQuery320workers. The naming convention is as follows: Animal Classified + Number of Breeds + Comparison Query Method + Number of workers. It is still vague as to which one we will use for our project but they are all very similar in some sense. Each file has 6 variables:
- Adj: Adjacency matrix under standard rules (and -1 = unobserved)
- AdjWithMultiples: Adj with entries observed more than once due to random queries
- CAdj: logical, mapping matrix to tell if an edge is observed (1) or not (0)
- count: number of edges observed (no multiples)
- groundtruth: actual breed of the animal
- m: number of nodes in the graph
Above demonstrates how MTurk works
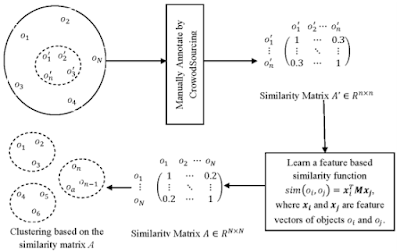
This dataset is useful because it does a lot for us already. Rather than waiting for god knows how long, 14773 edges are labeled through comparison (either by pairs or triangles). One small thing we will use on the dataset is making unobserved edges into no-edges. We do an entrywise multiplication of Adj with CAdj which leaves us with a cleaned adjacency matrix. This way, we avoid -1's and assume they are 0.

A big problem at hand is knowing what file we should work on. The four are offered but I would rightfully assume that one will be focussed on. It is a bit unclear as to what are the pros and cons of using an edge query and triangle query which factors into our final decision. My team and I are also fairly new to MatLab so much of the steps we need to take to run spectral clustering or some algorithm are unclear.
In conclusion, the presented dataset consists of adjacency matrixes with a total of 342 (for birds) or 473 (for dogs) nodes. They form graphs that can be clustered into 5 (for birds) or 3 (for dogs) classes. We plan to implement semi-crowdsourced clustering as our method of choice.

Image of my MatLab window. The Command Window displays the calculation we would need to do to clean the dataset.
A big problem at hand is knowing what file we should work on. The four are offered but I would rightfully assume that one will be focussed on. It is a bit unclear as to what are the pros and cons of using an edge query and triangle query which factors into our final decision. My team and I are also fairly new to MatLab so much of the steps we need to take to run spectral clustering or some algorithm are unclear.
In conclusion, the presented dataset consists of adjacency matrixes with a total of 342 (for birds) or 473 (for dogs) nodes. They form graphs that can be clustered into 5 (for birds) or 3 (for dogs) classes. We plan to implement semi-crowdsourced clustering as our method of choice.


Comments
Post a Comment