Crowd-source Image Labeling [Technical Journal]
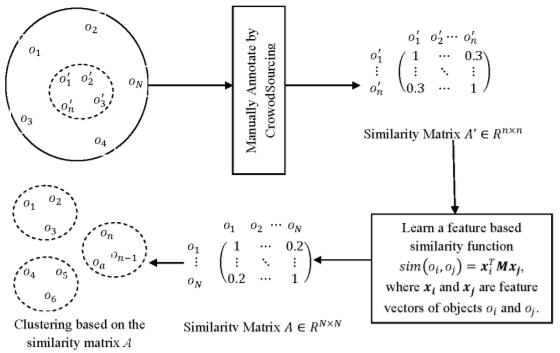
The question at hand is how to increase crowdsourcing image labeling efficiency which has been an apparent issue in Machine Learning. Steps taken have revolved around solving highly variable accuracy of the data. The paper "Crowdsourcing – A Step Towards Advanced Machine Learning" briefly talks on how has crowdsourcing is used in the real world. "On the Efficiency of Data Collection for Crowdsourced Classification" uses the most common data policies for crowdsourced classification on datasets and compares their accuracy to conclude each policy's lower and upper bounds as well as adaptive policies out-perform those that do not. "Distance Metric Learning: A Comprehensive Survey" lists out algorithms utilizing a distance metric and its summary, works, strengths, and weaknesses. "Semi-Crowdsourced Clustering: Generalizing Crowd Labeling by Robust Distance Metric Learning" touches upon the issue that data clustering has trouble finding a true similarity between data. Crowdclustering is the answer to the problem by comparing data using its labels as a pairwise similarity but requires data to be labeled. It suggests semi-crowdsourced clustering to decrease potential costs and generalizes large datasets. These papers push the possibility of crowdsourced image labeling to be more efficient. We will attempt to implement the framework of comparing different algorithms to optimize. However, to iterate on previous work, we expect to use spectral clustering. The framework used by the source on semi-crowdsourced clustering is pictured below.
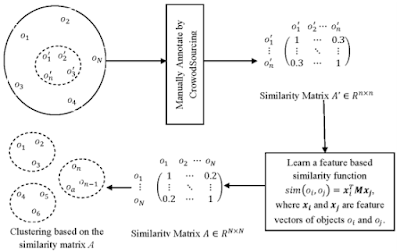
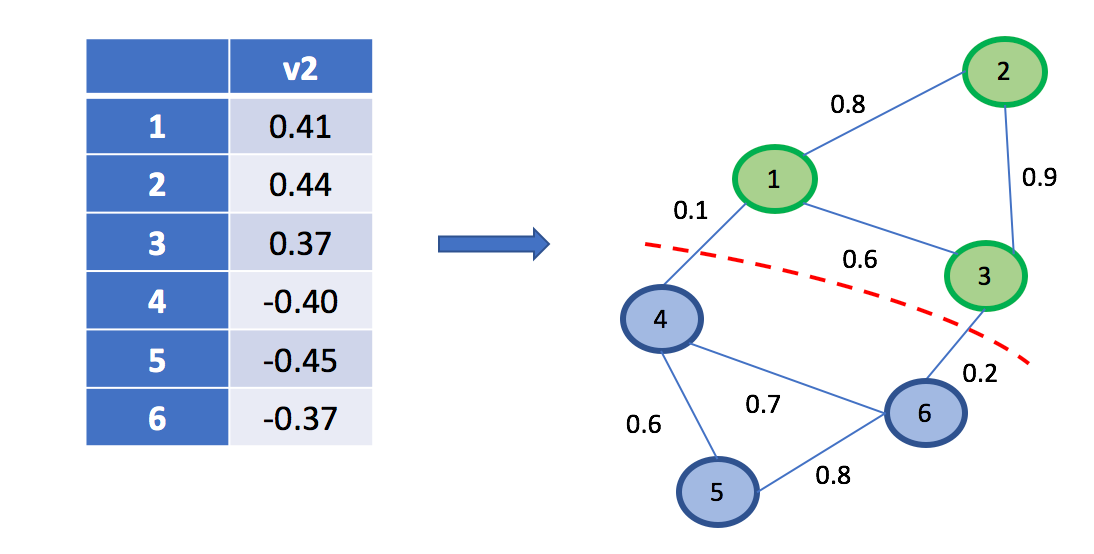
Semi-crowdsourced clustering was a method proposed earlier. Through clustering small objects, ultimately finding their labels, it later attempts to cluster a collection of objects. The algorithm is annotated manually, consists of partial similarity matrixes, and is generalized. The reason why this method is helpful is that it allows for a flexible budget (due to it only being partially crowd-sourced). An idea we had was to use spectral clustering because of its use of eigenvalues & eigenvectors to identify cliques. This process will remove major errors the algorithm may have made between clusters, reduce dimensionality, and divide data. Below is an image of spectral clustering partitioning a graph into two cliques:
We will be using the Dogs vs. Cats photo dataset from Kaggle Asirra (2007), a CAPTCHA developed as an alternative to text. The CAPTCHA has a database of over 3 million photographs from petfinder.com that have been manually annotated as cats or dogs. The problem can be made more challenging by going from just differentiating cats and dogs to specific breeds. The dataset has 3 million images but can be reduced to 25,000 or so or even lower. The bigger the size, the more costly it might get but rewarding. Ground truth is provided which is essential to our process. We expect crowdsourcing these simple tasks to be simple and requiring little teaching. Conflicts in the future may be gathering breed information and labeling such. Again, this poses potential costs that exceed what we had in mind. A way to do this is by using Amazon's resources like MTurk. During the meeting with Dr. Hassibi, we discussed the possibility of pre-labeled data from a graduate student which substantially reduces costs but it is unclear as of now. A sample of the pictures found in the dataset is below.

After implementing a framework for labeling and clustering the dataset between cats and dogs, we can invest our time transitioning from pairwise (2) comparison to three animals. This also entails that we use more than one dataset (such as ImageNet) so as to provide the integrity of the project. Data labeling, one of the most pressing issues in ML research, is known to be expensive and time-costly and in crowdsourcing, unreliable in some ways. We hope that future research can propel advancements in such areas. New problems with crowdsourcing image labeling not present in the Dogs vs. Cats dataset are bound to occur but are unknown to the human eye yet.
We will be using the Dogs vs. Cats photo dataset from Kaggle Asirra (2007), a CAPTCHA developed as an alternative to text. The CAPTCHA has a database of over 3 million photographs from petfinder.com that have been manually annotated as cats or dogs. The problem can be made more challenging by going from just differentiating cats and dogs to specific breeds. The dataset has 3 million images but can be reduced to 25,000 or so or even lower. The bigger the size, the more costly it might get but rewarding. Ground truth is provided which is essential to our process. We expect crowdsourcing these simple tasks to be simple and requiring little teaching. Conflicts in the future may be gathering breed information and labeling such. Again, this poses potential costs that exceed what we had in mind. A way to do this is by using Amazon's resources like MTurk. During the meeting with Dr. Hassibi, we discussed the possibility of pre-labeled data from a graduate student which substantially reduces costs but it is unclear as of now. A sample of the pictures found in the dataset is below.


Comments
Post a Comment