Technical Journal - Research Papers
On the Efficiency of Data Collection for Crowdsourced Classification:
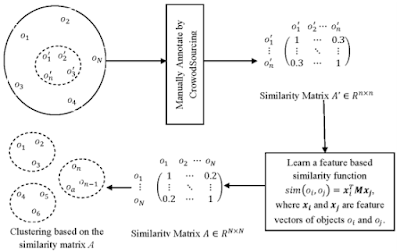
The issue the paper attempts to solve is defined as an appropriate similarity measure between two objects from crowd clustering. They resolve it by defining pairwise based on their manual labels but this poses another issue: The dataset must have labels. However, the paper describes the process of using semi-crowd clustering: using only a fraction of the dataset to be labeled and thus crowdsourced, it can then combine low-level features and learns a similarity measure based on them. The paper then notes that with crowd clustering, you limit yourself to manually annotated images/objects and large samples (since limited samples = large margin of errors). Semi-crowdsourced clustering is better because only a subset of images needs to be annotated, and then it can be applied to the entire dataset. The author writes that the first step is to obtain manual annotations, group objects based on visual similarity (manually through Human Intelligence Tasks). The pairwise similarity matrix is used to cluster data. It is based on manual annotations/labels so not the features of the objects.
Steps of Semi-crowdsourced clustering (Figure 1 shows an outline):



The paper aims to explain the accuracy gaps between popular collection policies (state-action mapping) on crowdsourced data. The quality of crowdsourced data is often highly variable so it is suspected that it is the cause. However, studies show that the policies used to collect such data have a strong impact on the accuracy of the system. The first theoretical explanation of the accuracy gaps is that the non-adaptive uniform allocation, and the adaptive uncertainty sampling and information gain maximization. Done with the representation of the collection process in terms of random walks in the log-odds (log of odds of guessing correctly/incorrectly) domain, the author derives lower and upper bounds on the accuracy of the policies. The bounds accurately tell us by how much do two adaptive policies trump a non-adaptive one. It is believed that techniques used by them are applicable to additional scenarios such as crowdsourcing models. This makes this research paper viable for our research.
The paper starts off by stating the issue that too many algorithms rely on distance metric learning. It notes that studies have demonstrated, both empirically and theoretically, that a learned metric can significantly improve the performance in areas such as classification and clustering. This paper surveys the field of distance metric learning from a principle perspective and includes a broad selection of recent work. In particular, distance metric learning is reviewed under different learning conditions: supervised learning versus unsupervised learning, learning in a global sense versus in a local sense; and the distance matrix based on linear kernel versus nonlinear kernel. In addition, this paper discusses a number of techniques that are central to distance metric learning (like convex programming, positive semi-definite programming, kernel learning, dimension reduction, K Nearest Neighbor, large margin classification, and graph-based approaches).
Steps of Semi-crowdsourced clustering (Figure 1 shows an outline):
- Select a small sample of the objects to be clustered
- Get their labels via crowdsourcing
- Discover an object feature vector
- Learn a pairwise similarity function from that subset
- Cluster the rest of the objects with such
- Use distance metric learning (learning a linear similarity function from given pairwise similarities)
Noise from pairwise similarities from manual annotations disrupts results but studies show that a metric learning algorithm can solve such. The proposed algorithm uses the matrix completion technique to rectify the noisy pairwise similarities, and regression analysis to efficiently learn a distance metric from the restored pairwise similarities. This has three benefits: (1) the proposed algorithm is robust to a large amount of noise in the pairwise similarities, (2) by utilizing regression analysis, the algorithm is computationally efficient and does not meddle with the positive semi-definite constraint, and (3) it is close to the optimal metric learned from the perfect or true similarities. A general framework is in Figure 2. The results of the model are shown in Figure 3.

Figure 1. framework for semi-crowdsourced clustering

Figure 2. framework for learning a distance metric from noisy manual annotations

Figure 3. Sample image pairs are incorrectly clusted by base method but correctly guessed by the proposed algorithm, tangible proof
The most obvious question to be asked is how can I use these papers for our project. That's something we will have to work out in the near future. I have a vague idea but it's too hard for me to type it down here. It's a mess in my head right now. Troubles we'll have is if we randomly choose data to be annotated (semi-sourced clustering), how will different scenarios affect the overall performance of the algorithm?


Comments
Post a Comment